The iOS Battle.net app keeps message related data in the ZMESSAGE and ZUSER tables from the following SQLite database:
/private/var/mobile/Containers/Data/Application/UU-ID/Documents/Social.sqliteThe process to obtain the correct UU-ID number is presented in brief in the long version section. For a detailed example see here.
Queries that can be used as templates to extract messages from the database can be found at:
https://github.com/abrignoni/DFIR-SQL-Query-Repo/tree/master/iOS/BATTLE.NETLong version
Blizzard properties are one of the most popular in the computer and video gaming community. The Battle.net app was developed as a way for gamers to communicate via chat messages.
 |
| Stay connected with your friends wherever you are. |
Testing Platform
For analysis I am using the following device and equipment:
- iPhone SE - A1662
- iOS 11.2.1
- Jailbroken - Electra
- Forensic workstation with Windows 10 and SSH software.
Acquisition
A brief overview of the identification and extraction of Battle.net user data app directory is as follows. For an detailed example see here.
1. Locate bundle id name.
A brief overview of the identification and extraction of Battle.net user data app directory is as follows. For an detailed example see here.
1. Locate bundle id name.

2. Access the 'applicationState.db' file located at:

This SQLite database provided the connection between the bundle id and the UU-ID numbers in the 'Application' directory.
Open the SQLite database with a SQLite browser. Look for the bundle id name in the 'application_identifier_tab' table. Take note of the corresponding id number.
3. Look for it in the 'kvs' table in the 'application_identifier' field . Export the blob in the value field for the id. The exported data is a bplist that maps all pertinent UU-ID numbers to the application name and/or bundle id. The data can also be seen in the preview pane in binary mode without the need to export the blob content. If the bplist is exported a viewer, like Sanderson Forensics BPlister, can be used to see the relationship between UU-ID and application we are looking for.
/private/var/mobile/Library/FrontBoard/

This SQLite database provided the connection between the bundle id and the UU-ID numbers in the 'Application' directory.
Open the SQLite database with a SQLite browser. Look for the bundle id name in the 'application_identifier_tab' table. Take note of the corresponding id number.
3. Look for it in the 'kvs' table in the 'application_identifier' field . Export the blob in the value field for the id. The exported data is a bplist that maps all pertinent UU-ID numbers to the application name and/or bundle id. The data can also be seen in the preview pane in binary mode without the need to export the blob content. If the bplist is exported a viewer, like Sanderson Forensics BPlister, can be used to see the relationship between UU-ID and application we are looking for.

4. With the correct application directory identified I copied it via SSH to the forensic workstation.
In this particular instance I did not make a full file system extraction of the device. I only copied the app directory of interest for testing purposes. Do follow generally accepted forensic principles when doing similar work on your case work.
Messages and user data
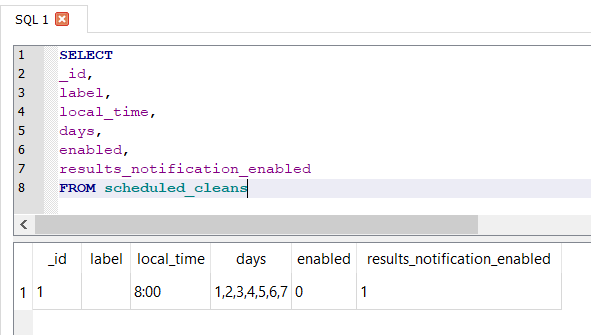
Messages and user data are contained in the Social.sqlite database. Using the templates located at the links at the beginning of the blog the following results are obtained:
The column data is as follows:

Messages and user data
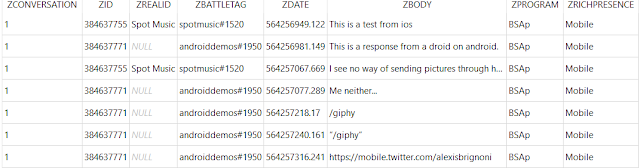
Messages and user data are contained in the Social.sqlite database. Using the templates located at the links at the beginning of the blog the following results are obtained:
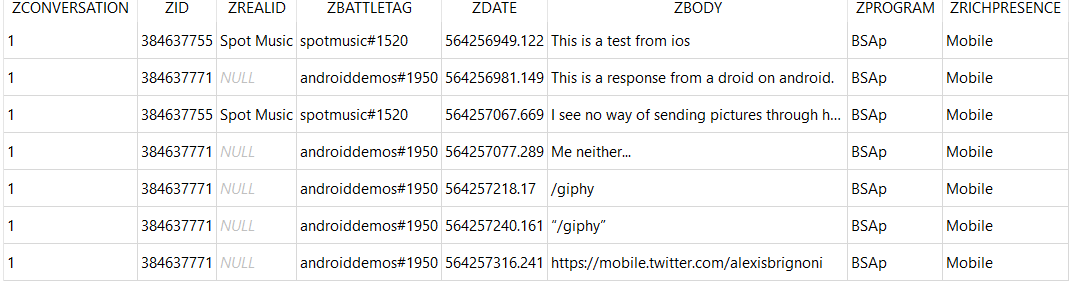
The column data is as follows:
- ZCONVERSATION = Keeps tracks of messages between a unique set of users.
- ZID = Internal user ID number.
- ZREALID = Real ID for contact. For details on Real ID see here.
- ZBATTLETAG = ID used to add other app users to your contacts list.
- ZDATE = Message date.
- ZBODY = The message.
- ZPROGRAM = Program used.
- ZRICHPRESENCE = Details regarding the program used.
For user details the query at the beginning of the post produces the following:

The column data is as follows:
- ZID = Internal user ID number.
- ZREALID = Real ID for contact. For details on Real ID see here.
- ZBATTLETAG = ID used to add other app users to your contacts list.
- ZISFAVORITE = User favorites.
- ZNOTE = User generated description of another user in their list.
- ZPROGRAM = Program used.
- ZRICHPRESENCE = Details regarding the program used.
While using the app I was not able to find a way to send other media types, like videos or pictures, to another user.
Conclusion
Gaming and gaming communication apps have exploded in regards to the amount of users in the last few years. Some of these platforms are rivaling other more established ones whose only purpose is communication. Examiners need to aware that these apps might contain relevant information. We should not be deceived by their gaming-centric presentation. Plenty, if not most of this apps, have all sorts of user generated content that we should take into consideration.
As a way of facilitating access to the content these databases hold I have submitted and had approved custom artifacts for the Magnet Forensics Axiom software. These custom artifacts can be found in the Artifact Exchange page.
As always I can be reached on twitter @alexisbrignoni and email 4n6[at]abrignoni[dot]com.