The Android Nike apps keeps geolocation data in the following location and files:
/userdata/data/com.nike.plusgps/databases/com.nike.activitystore.database - SQLite database
- Tracks latitude, longitude, distance, calories and a multitude of different metrics for runners.
To select the latitude and longitude coordinates for any recorded run the following query can be used:
CREATE VIEW sub1
as
SELECT * FROM activity_raw_metric, activity_metric_group
WHERE activity_raw_metric.rm_metric_group_id = activity_metric_group._id and activity_metric_group.mg_activity_id = integer_value_of_interest
ORDER BY activity_raw_metric.rm_start_utc_millis;
SELECT datetime(lat.rm_start_utc_millis / 1000, 'unixepoch', 'localtime') as day, lat.rm_value as latitude, long.rm_value as longitude
FROM sub1 as lat left join sub1 as long on lat.rm_start_utc_millis = long.rm_start_utc_millis
WHERE lat.mg_metric_type = 'latitude' and long.mg_metric_type = 'longitude'
ORDER BY lat.rm_start_utc_millis;
DROP VIEW sub1;
- In order to identify what values of latitude and longitude correspond to a particular run a VIEW is used where the integer value for mg_activity_id identifies such a run uniquely. In the query above one has to substitute integer_value_of_interest with the integer that represents the run we want to extract.
- The second SELECT is a self join that places latitude and longitude values for a specific point in time in one row. This makes exporting the data to mapping applications possible since most of these expect a pair of geolocation values per row.
Below is a python script that parses com.nike.activitystore.database and generates multiple CVS files with the date, time, latitude and longitude values for all runs. No need to manually change the integer_value_of_interest. The script produces one CSV file per run which can be imported to a mapping application like Google Earth for visualization.
Long version:
This post is the logical continuation of my previous iOS Nike Run app - Geolocation & self join query entry. The purpose is to find geolocation artifacts for app recorded runs. Be aware that the app contains many more metrics of possible interest beyond GPS coordinates.
Testing platform
Details of hardware and software used can be found here.
Extraction and processing
Magnet Forensics Acquire - Full physical extraction.
Autopsy 4.8.0
Analysis
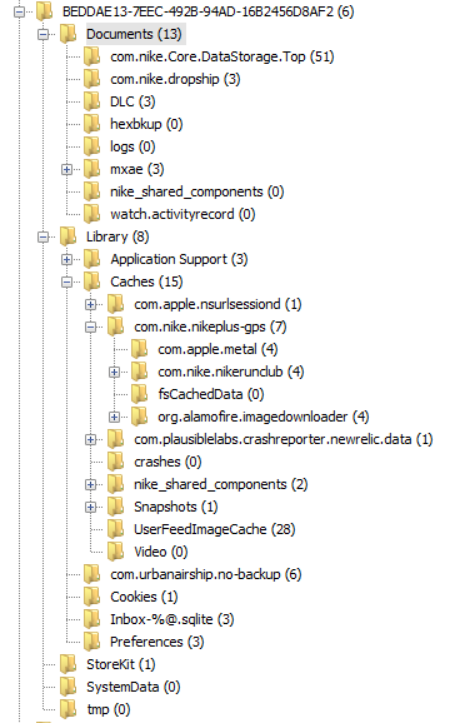
The Nike Run user and application directories were located at:
userdata/data/com.nike.plusgps
|




Unlike the database for iOS this first query produces the initial result set by combining to tables. Since this initial query is a join of two tables and in order to place the longitude and latitude value pairs in rows we make a VIEW out of it as so:
CREATE VIEW sub1
AS
SELECT * FROM activity_raw_metric, activity_metric_group
WHERE activity_raw_metric.rm_metric_group_id = activity_metric_group._id and activity_metric_group.mg_activity_id = 23
ORDER BY activity_raw_metric.rm_start_utc_millis;
It is the same query as before but adding the CREATE VIEW AS at the start. Now that we have a view we can reference it by the name we gave it of sub1 and do a self join query on it.
SELECT datetime(lat.rm_start_utc_millis / 1000, 'unixepoch', 'localtime') as day, lat.rm_value as latitude, long.rm_value as longitude
FROM sub1 as lat left join sub1 as long on lat.rm_start_utc_millis = long.rm_start_utc_millis
WHERE lat.mg_metric_type = 'latitude' and long.mg_metric_type = 'longitude'
ORDER BY lat.rm_start_utc_millis;
DROP VIEW sub1;This query does a self join on the date-time values since for every point in time there will be a set of coordinates to map. Also I took the opportunity to add a field to the result where the time is changed from UTC to local time. When I'm done with the view I delete it.
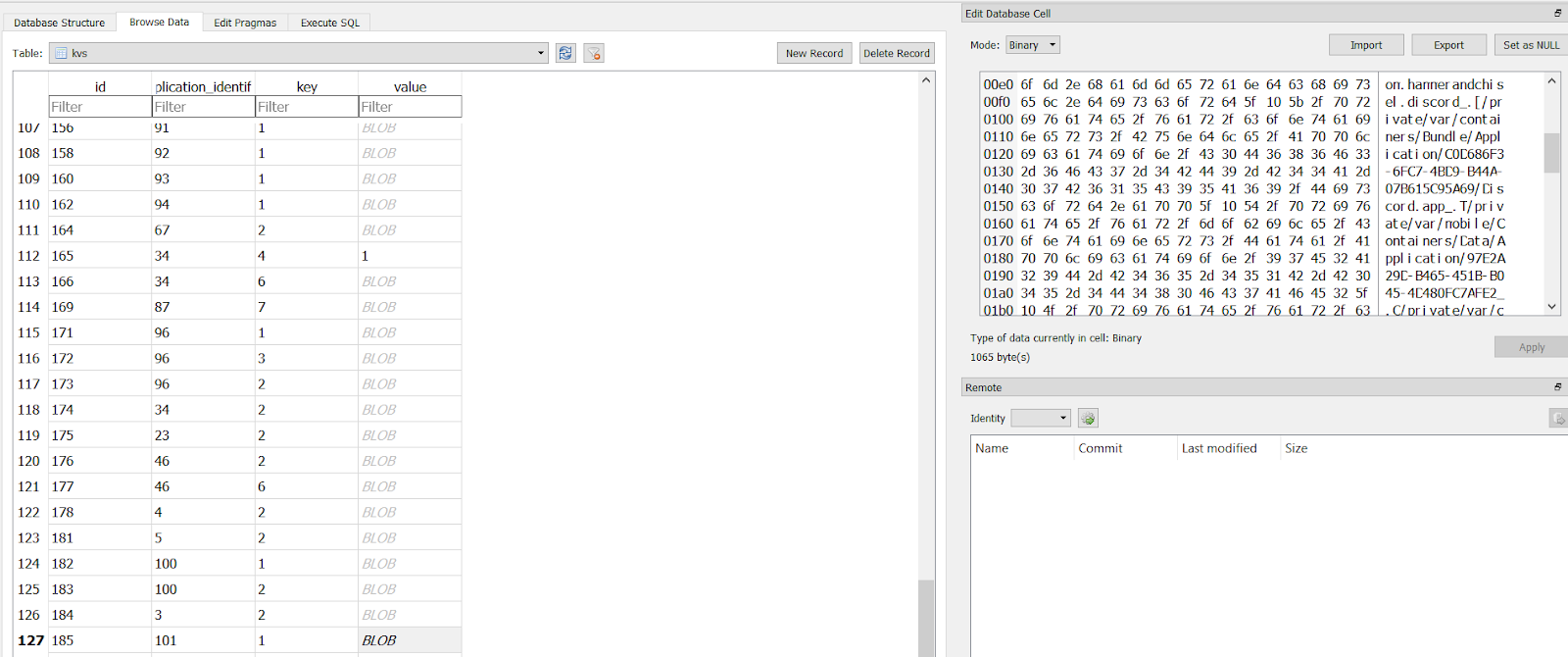
The image above combines the two queries just described and shows how geolocation values, with their corresponding date-times, are consolidated by row.
 |
| Notice result at bottom. |
What if we want to export all runs with their values as just seen and not just one run at a time? Changing the mg_activity_id value in the create view query run by run gets old pretty quick. In order to automate it a little I made a script that selects all run numbers first and then exports all values per run automatically. The values are exported as CSV files whose filenames are the date and time of the start of the run they represent.
The script can be found here:
https://github.com/abrignoni/NikeRunApp-GeoparserExport the database and put it in the same directory as the script. Run the script and when it ends one should see the created CSV files as seen below, one per run for all runs.
 |
| Look at all those CSVs! |
 |
| Google Earth |
This analysis tell us NOTHING about what device was used to record this data within the app.
As a matter of fact none of the runs in my test device were made with it. Just because an app registers geolocation data does not mean the device in which the data was found was the one used to generate it. App synchronization requires the examiner to be really careful before making causal determinations. As always careful testing and validation is necessary.
BIG BIG CAVEAT #2

Super important. In order to not miss evidence of possible deleted records do use a forensic SQLite tool to explore WAL records.
As always I can be reached on twitter @alexisbrignoni and email 4n6[at]abrignoni[dot]com.