Virtual Analyzer (VA) is an Android emulator that works within Cellebrite Physical Analyzer (PA). It provides a convenient way to look at data logically (no deleted/recovered items) as the user would have seen it through the app itself. This blog post will briefly detail my initial interactions and reactions regarding the use of the tool.
Installation notes will be at the end of the post.
Testing
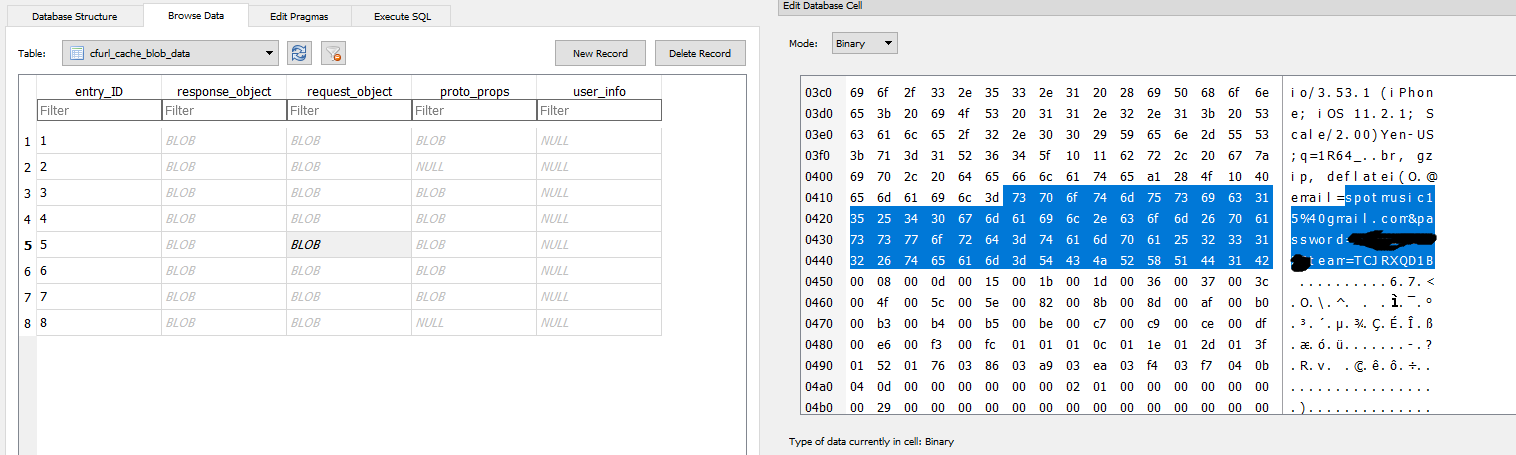
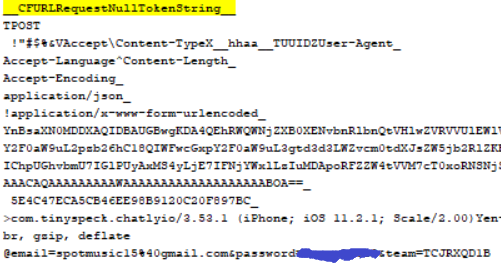
For this test I used one of my Android physical extractions that contained some sample data used for previous app reviews in this blog. I opened PA and pointed it to the physical extraction and let it parse. When it was done the VA option was available under the tools menu.

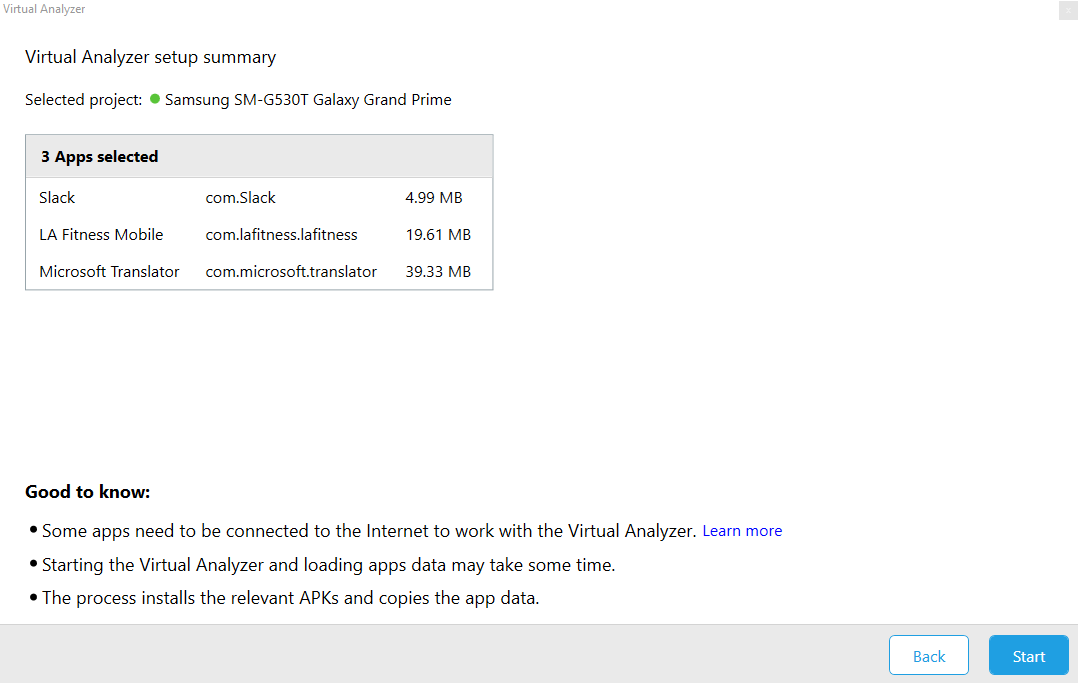
After the initial splash screen shown above, the tool lets you choose up to 5 apps to emulate at one time. For my initial run I selected the following 3 apps: Slack, LA Fitness Mobile and Microsoft Translator.
 |
| Select your apps. |
The interface was clean and consistent with the PA screens I am already used to. After selection the next screen shows how much data will the emulator work with per app.
 |
| Notice the 'good to know.' |
Processing took a little bit of time but even so it was still way, way, way quicker than doing a similar analysis by 'hand' as I have done here.

As VA starts you will see a progress bar show up on the lower right corner of the screen. When completed a window opens that has the emulated system ready for user interaction.

The selected apps will show up on the home screen and one has only to click them as one would in any Android system. By looking at the setting I noticed that the emulation was done via the use of the Andy Android emulator.

Going back to the home screen I interacted with the apps. All three worked and presented to me the data I expected to see it based on my previous non-emulated analysis. Here is how it looked per app. A link to non-emulated analysis is provided as a comparison.
Microsoft Translator
Click for the non-emulated analysis of Microsoft Translator.
Emulated analysis image for Microsoft Translator:
| All the options in the app worked. |
LA Fitness Mobile
Click for the non-emulated analysis of LA Fitness mobile.
Emulated analysis image for LA Fitness mobile:

In this instance looking at check-in data through the emulated app was harder and slower than looking at it when extracted directly since it requires no screen manipulation. Still the analysis validation provided by this tool is immense. A long excel like report with dates and data can be validated by looking at a portion of it through the emulated app itself.
Slack
Click for the non-emulated analysis of Slack.
Emulated analysis image for Slack:

I really liked being able to see the images properly placed within their corresponding Slack messages. I have yet to find a way to do such a image placement manually by only looking at the content of the databases themselves. Emulation solves this problem.
To finish my testing I looked at two more apps, Discord and Nike Run. Discord behaved as the previous apps, the emulator showed me the content as expected.
Discord
Click for the non-emulated analysis of Discord.
Emulated analysis image for Discord:

As Discord seems to be showing up more and more in colleagues' case work being able to access it in this way is invaluable. In some instances emulation might be the only way of presenting the data absent an actual manipulation and screen recording of the device.
Nike Run
Click for the non-emulated analysis for Nike Run.
Emulated analysis image for Nike Run:
 |
| Womp, womp. |
The emulation for the Nike app kept crashing and did not work. Using PA I looked at the database and the required data was there.
 |
| Time, GPS, speed, etc... |
In this instance a database extraction paired with a custom SQL query was the ideal analysis method. It seems the app itself requires a connection to an external server before it initiates. VA, being a forensic tool, does not allow such a thing to happen. To permit the host system that runs PA/VA and the emulator to be connected to the Internet (they shouldn't be as a matter of course) can bring up issues regarding the illegal search of a remote system. Always be aware what you do, how you are doing it and under what authority you are operating. Such things cannot be overlooked.
Conclusion
There is no ultimate one-in-all forensic tool and most likely there will never be one. As examiners we need to exercise proper judgment on how we go about our work and what will the ideal tools be for a particular case or work scenario. It seems to me that Virtual Analyzer is poised to become one of those essential tools in our forensic toolbox.
If we could only have something similar for iOS....
As always I can be reached on twitter @alexisbrignoni and email 4n6[at]abrignoni[dot]com.
Installation Notes
Installation was easy but required a little tinkering. After downloading the executable from the Cellebrite portal I tried to, mistakenly, install it in a system that had a previous PA version than the current and required 7.10. Instead of getting an error of 'update to current version' I got the following:
After noticing my mistake I upgraded to the latest version and the software almost installed. After some emails with support I found out that the Android emulator requires VMware Player to run. The error was caused due to my previously installed version of VMware Workstation 12.5.9 not being compatible. Currently VA works with VMware Player versions 12 to 14 and developers are currently working on a solution to have VA work with the latest release, version 15, of VMware Player. Since I couldn't uninstall Workstation 12 for reasons I moved to another system and did a clean installed of all the required software. This was my procedure:
Installation Notes
Installation was easy but required a little tinkering. After downloading the executable from the Cellebrite portal I tried to, mistakenly, install it in a system that had a previous PA version than the current and required 7.10. Instead of getting an error of 'update to current version' I got the following:
 |
| Fair enough, it was my fault initially... |
- Download and install VMware Player version 14.
- Download and install PA.
- Download and install VA.